Das von der EU-Kommission geförderte Forschungs- und Innovationsprojekt TROMPA (Towards Richer Online Music Public-domain Archives1) möchte eine digitale Plattform schaffen, auf der die Digitalisierung, Vernetzung und Anreicherung aller Erscheinungsformen von klassischer Musik (wie Partituren und Tonaufnahmen) von jeder/jedem selbst mitgestaltet werden können.
Die klassische Musik ist ein kostbarer Teil unseres kulturellen Erbes. Dieses wird jedoch keineswegs in unveränderter Form überliefert, sondern ist durch Forschung, ständige Neu-Interpretation, Wiederaufführung, und letztendlich durch den breiten Hörgenuss einem permanenten Wandel unterworfen, der es auf vielfache Weise aktualisiert und weiterleben lässt. Klassische Musik ist im Internet an vielen Orten und in vielerlei Gestalt anzutreffen: Musikbibliotheken und Archive (wie beispielsweise IMSLP2 oder die British Library3) sammeln und bewahren Notendrucke, Handschriften oder andere Quellen und stellen diese in digitalisierter Form der Öffentlichkeit zur Verfügung. Online-Plattformen wie YouTube oder Spotify bieten Aufnahmen klassischer Musik in audio-visueller Form mit den dazugehörigen Metadaten (Titel, Interpret_in, Komponist_in) an. Diese unterschiedlichen Quellenarten sind allerdings kaum miteinander verknüpft und bieten nur wenige Möglichkeiten zur persönlichen Interaktion.
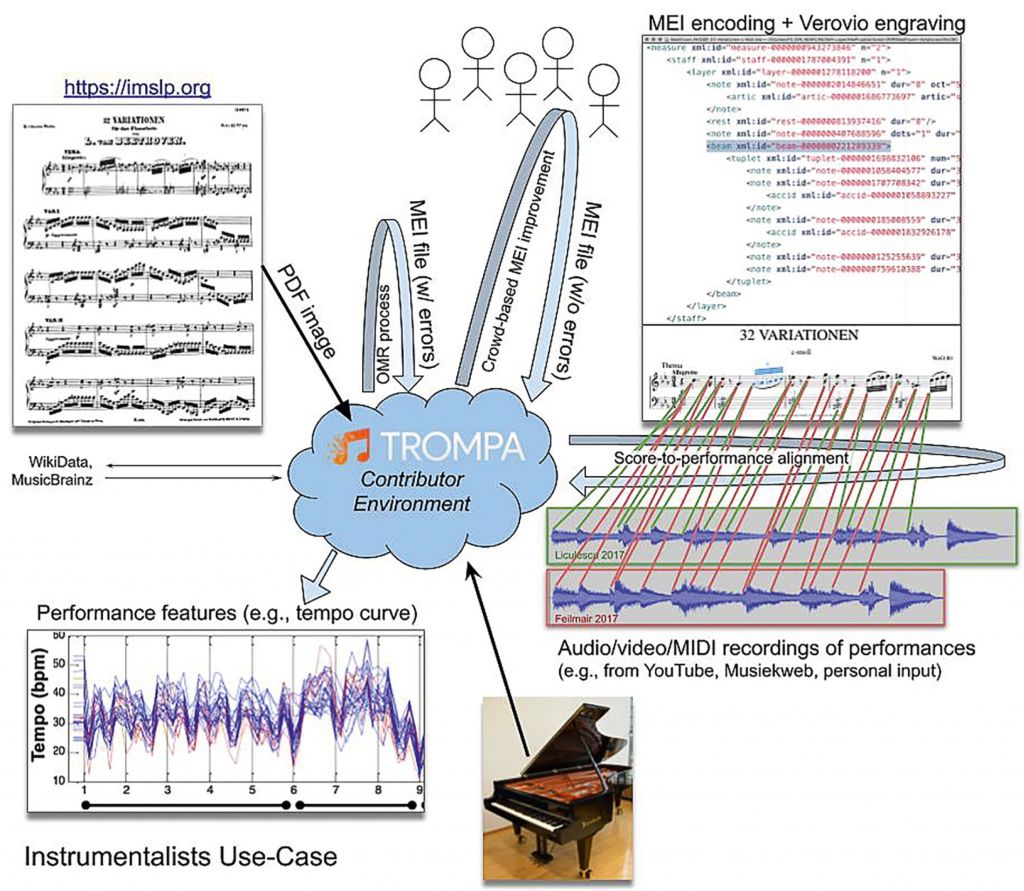
Das Ziel von TROMPA ist es, modernste Music-Information-Retrieval(MIR)- und Crowd-Sourcing-Technologien einzusetzen, um gemeinfreie digitale Partituren unseres musikalischen Erbes zu generieren (im musikwissenschaftlichen MEI-Format4) und diese durch Crowd-Interaktion auf ein solides Datenniveau zu heben und von Fehlern zu befreien. Die unterschiedlichen Modalitäten (Partituren, Aufnahmen) werden miteinander verknüpft und synchronisiert (Score-to-Performance-Alignment) und durch vielfältige Annotationen durch die „Crowd“ angereichert (siehe Abb. 1). Damit wird die Grundlage für vielfältige webbasierte Computeranwendungen geschaffen.
Das Contributor Environment orchestriert Daten, Quellen und Prozesse
Die zentrale Koordinationsstelle im TROMPA-Datennetzwerk ist das sogenannte Contributor Environment (CE), durch das alle externen Inhalte (Aufnahmen, Partituren etc.) verlinkt, Metadaten zu Werken oder Aufnahmen mit anderen gemeinfreien Datenrepositorien wie Wikidata oder MusicBrainz verknüpft und automatische Prozesse wie optische Notenerkennung oder Score-to-Performance-Alignment initiiert werden. Auch wenn im CE keine Daten selbst gespeichert sind, sondern nur die Verknüpfungsinformationen, können alle Inhalte zentral gesucht und verwaltet werden. In der Organisation der Daten werden wichtige Informationsstandards eingehalten: Web-3.0-Standards wie Linked Data und Semantic Web, das FAIR-Prinzip (Daten müssen findable – auffindbar, accessible – abrufbar, interoperable – kompatibel und reusable – wiederverwertbar sein) und Open Data (möglichst viele generierte Daten und Repositorien sollen gemeinfrei und allgemein zugänglich sein – die explizite Zustimmung der teilnehmenden Musizierenden vorausgesetzt).
Fünf Zielgruppen, fünf Use-Cases
TROMPA hat fünf Zielgruppen vor Augen, die jeweils mit einem eigenen Use-Case, einem Anwendungsbeispiel bedacht werden: Instrumentalist_innen, Musikgelehrte, Orchester, Chöre und Musik-Begeisterte. Alle Use-Cases greifen dabei auf das zentrale CE zu und bauen ihre Anwendungen webbasiert darauf auf.
Ein Performance-Companion für Pianist_innen
Das Institut für musikalische Akustik – Wiener Klangstil (IWK) ist für den Instrumentalist_innen-Use-Case verantwortlich, in dem ein Performance Companion, eine Art digitale Assistenz, sowohl für einzelne Musizierende als auch für Ensembles, die beim täglichen Üben und Proben zum Einsatz kommen soll. Zur Veranschaulichung: Eine Pianistin übt ein neues Stück, sagen wir Beethovens Appassionata. Sie wählt die Partitur auf ihrem Tablet-Computer aus (falls diese noch nicht vorhanden ist, lädt sie eine gescannte Version in das CE hoch und verbessert in der automatischen MEI-Konvertierung die gröbsten Fehler über ein Webinterface rasch selbst, weitere Fehler werden später von der Crowd noch behoben). Während sie übt, wird ihre Performance in Form von Audio- oder symbolischen Aufführungsdaten an einen Alignment-Prozess im CE gestreamt, der die Performance mit der MEI-Partitur synchronisiert. Nachdem sie aufgehört hat zu spielen, studiert sie die sofort angezeigte notengenaue Tempokurve ihres Performance-Ausschnitts. Dann wählt sie aus mehreren anderen Aufführungen auf YouTube oder Spotify ihre Lieblingsaufführung des Stückes, zum Beispiel die von Claudio Arrau, aus und erhält Arraus Tempokurve, die sie mit ihrer eigenen Aufführung vergleichen kann. Während sie Arraus Performance hört und seine Tempokurve beobachtet, schreibt sie einen Kommentar zu einer bestimmten Stelle in der Appassionata und erstellt eine Web-Annotation5, die sowohl auf den relevanten Ausschnitt der Partitur als auch auf Arraus Aufnahme zeigt und im CE gespeichert ist. Ein Wissenschaftler, der diesen Abschnitt während eines Beethoven-Klaviersonatenprojekts analysiert, kann auf ihre (und andere) Anmerkungen zu Arraus Aufführung zugreifen, sie in seine Analyse einbeziehen und auf ihren Kommentar in seiner Publikation referenzieren.
Das TROMPA-Konsortium besteht aus vier akademischen Partnern (neben dem Wiener Institut sind es auch Partner aus Delft, Barcelona und London), drei Start-ups und zwei sogenannte Content Owners (darunter das Königliche Concertgebouw Orchester Amsterdam). TROMPA beendet derzeit das erste Jahr seiner Tätigkeit und wird bis Mitte 2021 laufen. Prototypen der einzelnen Use-Cases sind bereits weitgehend implementiert. Um jene Skalierbarkeit zu erreichen, die das Projekt für die verschiedenen Anwendungsgruppen wirklich nützlich macht, müssen noch einige technische Herausforderungen gelöst und vor allem eine große Gemeinschaft von Musikbegeisterten aller Fachrichtungen und Kontexte gebildet werden, die dann in der Lage sein wird, ein umfassendes Archiv von gemeinfreien Partitur-Kodierungen aufzubauen, es großflächig mit Aufnahmen zu verknüpfen und mit zahlreichen persönlichen Kommentaren anzureichern. Wer die Digitalisierung und Anreicherung unseres musikalischen Erbes innerhalb des TROMPA-Netzwerks mitgestalten will, kann sich unter trompamusic.eu informieren.